This second post describes stuff, issues, advice in putting into practice feature flags. At the end of the creation, implementation and testing steps, we will have feature flags ready for the next step: rolling out a new feature.
Creating
Naming
The first step in feature flag creation is to create a naming convention.
Name given to a Feature Flag must be unique. A best practice is to use naming conventions for short vs long-term flags, including name of the service, the team…
Consistency is key, once defined a naming convention it must be kept.
In case of release feature flags, name can include the ticket number.
Ownership
By definition, we want to have each flag owned by a clearly identified team. That team is responsible for driving rollout of the feature, monitoring performance, and so on. Ownership of the flag should be clear for everybody.
There are exceptions to this rule. In case of dependencies (features implemented by different teams), we will explore the impact of sharing same feature flag. In case we decide to go ahead sharing a flag, we have to agree how to rollout it.
Implementing
At its core, feature flagging is about our software being able to choose between two or more different execution paths, based upon a flag configuration, often taking into account runtime context (for example which user is making the current web request).
Toggles should be implemented in the simplest way possible.
«Toggle tests should only appear at the minimum amount of toggle points to ensure the new feature is properly hidden. […] Do not try to protect every code path in the new feature code with a toggle, focus on just the entry points that would lead users there and toggle those entry points. If you find that creating, maintaining, or removing the toggles takes significant time, then that’s a sign that you have too many toggle tests»
Martin Fowler
We should try to centralize toggle check/test in one place and minimize where the toggles are used in code. The more code paths we have, the more places there are to test and the more potential bugs to come in. If the solution feels complex, the first task may be to simplify the implementation.
Implement Flagging Decisions Close to Business Logic
Make the flagging decision as close to the business logic powering the flag, while still retaining sufficient runtime context (user, remote address…) to make the flagging decision.
This ensures that flagging decisions are encapsulated as much as possible while avoiding the need for every part of the codebase to be aware of the concepts like User, Account, Product Tier, and so on, which often help drive flagging decisions.
Following this rule of thumb is sometimes a balancing act. We usually have the most context about an operation at the edge—where the operation enters our system. In modern systems, however, core business logic is often broken apart into many small services. As a result, we need to make a flagging decision near the edge of the system where a request first arrives (i.e., in a web tier) and then pass that flagging decision on to core services when making the API calls that will fulfill that request.
Branch by Abstraction
Branching by abstraction is a pattern used for making large-scale changes gradually, while simultaneously continuing to release your application. This is an important part of trunk-based development and is critical for creating a continuous integration and continuous delivery (CI/CD) pipeline.
Imagine that we are refactoring a piece of the code with several modules that have dependencies on this code, old implementation, and we cannot risk breakage and we are not able to release the entire set of changes at once.
In order to manage our updates in a continuous integration environment, we could implement branch by abstraction:
- Identify the legacy system to be replaced
- Build an abstraction layer to allow continued communication between the systems that are being replaced and the entities requesting that service
- Methodically build the replacement system
- As code in the old systems become obsolete, delete it
- Once all of the old code has been removed, you can dismantle the abstraction layer
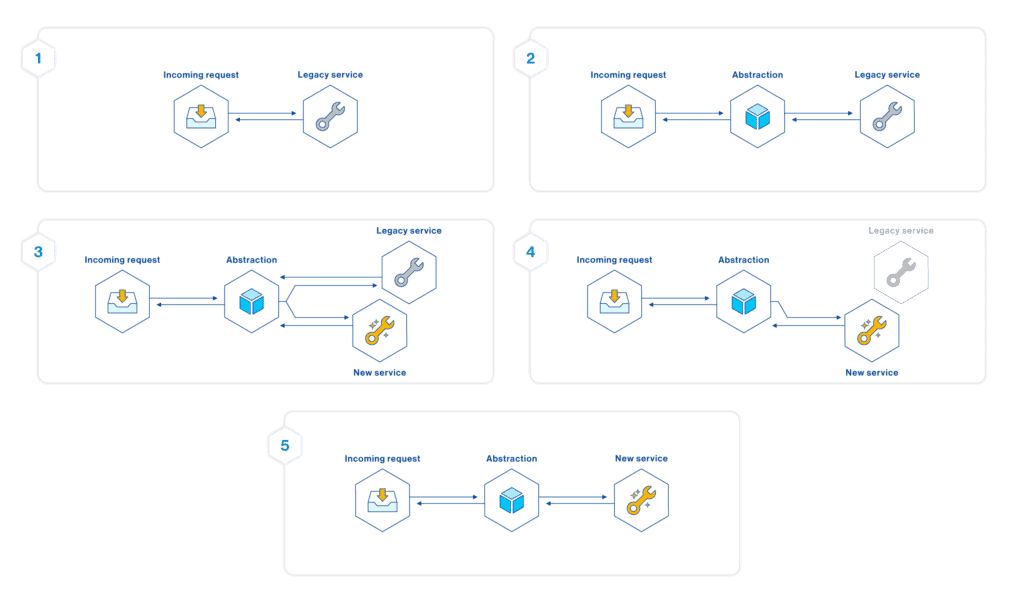
In the simplest case we can build the entire abstraction layer, refactor everything to use it, build the new implementation and then flick the switch. However, there are many variations on this process, where we apply this pattern for each affected part (separately).
In any case, the abstraction layer allows an easy transition between one implementation and another by allowing both to coexist in the same system.
Because we are only interfacing with the abstraction layer, merge conflicts are restricted to the abstraction layer.
Branching by abstraction is not always the best option, it requires an extra effort than just adding the toggle logic (if/else), developer has to evaluate whether it is worth introducing a design construct for this short period, only to delete it again shortly after, once the flag is removed.
Testing
Using Feature Flags, we are deploying features into production before they are finished. This is key for implementing continuous deployment: separating code deploy from feature release. By placing a partially implemented feature behind a flag, we can break that feature development into small chunks.
However, even if work is safely protected behind a flag, it still needs to be tested before it is released.
By using feature flags, we are creating a conditional alternative execution path. These alternatives create additional complexity when it comes to testing.
In feature flag testing, we have two main challenges to face:
- Test strategy: feature flags multiplies options to be tested. The more flags we have, the more combinations we could test. We cannot test all combinations; we need to define test strategies.
- Test process: how to perform tests (automated and manual) in all layers of the test pyramid.
Test Strategies For Automated Tests
It can be very challenging to do traditional automated integration testing with feature flags. We do not want to handle every possible case (any combination). Instead, a couple of strategies are outlined below:
- Disaster scenario: This defines which variation of a feature to serve in the event that for whatever reason we are not able to evaluate this flag. Testing against the “offline” state is a great way to ensure that your users will continue to have a sane experience even if all of your feature flags are in their default state.
- Production state: Running your integration tests against the current production state will provide you with some confidence that once you deploy into production, everything will still work. This step is key for enabling continuous deployment.
- Next release candidate: This scenario may change very quickly, it depends on the status of the in-progress developments. Collection of flags set to ON are: the ones enabled in production plus finished and not deployed developments (pending rollout) and finished developments pending to be certified (staging).
- Flush out: All flags ON. Used in the implementation phase for coding and testing the new feature. It can be also used to detect affected tests by a feature.
- Laboratories: We may need to execute our tests against specific setup of our flags, combining some of them. This strategy is open, not pre-defined like previous ones and there may exist more than one laboratory.
All kind of tests performed (except unit tests) can make use of these strategies.
Test Process
We can classify our tests in automated (unit, API, integration and End-to-end) and manual (User Acceptance Testing, Test in production).
During the development process, depending on the objective of the test, we will use one strategy or another. For testing in production, we will use a specific approach as part of the rollout process.
Test Automation With Feature Flags
We write automated tests to validate parts of business logic, automate user interaction to maintain an error-free user experience, and avoid introducing bugs as the codebase evolves. In this section, we discuss the implications of using feature flags in combination with known practices of continuous integration.
These automated tests are executed as a part of the Continuous Integration (CI) process.
There are a few goals we aim for:
- We want to make sure all currently tested paths affected by the flag are tested with the flag on and off.
- We do not want our test suites to become too large and/or hard to understand because of feature flags, that is why we base testing on defined strategies (see previous section).
- We want a repository history that is easy to understand despite the temporary complexity of a feature flag.
- Ideally, deleting a feature flag will be a quick task that requires no in-depth reading of the code or tests.
We can split automated test in two groups, depending whether the tests is executed against a piece of code (unit tests) or against a deployed and running instance (API, integration or end to end).
Unit tests
One of the KPIs used in unit tests is coverage, so, we have just to cover code with flag ON and with flag OFF.
Make a copy of every affected test
Do not try to to cover feature flag ON and OFF in one test (do not add “Feature X ON” test cases). Instead, make TWO test files: one for flag on, one for flag off. Yes, we will probably have a bunch of duplicated test cases that are the same in both files, maybe even most of them, but this is only temporary.
There are three benefits to this approach: First, we have avoided creating a confusing monstrosity of a test with flag on, flag off, and flag-agnostic tests all mingled in together. Second, once we have decided to keep the flag on permanently, we can just delete the whole “flag off” test file. “Simples!” Thirdly, we can do the setup for the flag once at the top of each test file, rather than having to set it at the start of each test case and hoping people notice that detail when reading the test.
Make the copied file tests the “Old” functionality, and the original file tests the “New”
When we make a copy of the existing test to a new file, we want to make the new file the tests for the old functionality — with the feature flag off and change the original test file to have the test cases for when the flag is on. This helps to keep a contiguous SCM history for the enduring test suite showing how the functionality progressed.
This is because, if we put the “feature flag on” test cases in the new file, then, when we get rid of the feature flag, deleting the original test and renaming the “new” one to the “normal” one, then, when looking at our repository history: it would often show the whole test being deleted then re-created, which makes it much harder to inspect what changes were made to the tests when the new change was introduced.
Reset flag status
At the end of any test that enables a feature flag, always set the flag back to what it was before the test started. This is important because, if our flags are stateful in a way that is not automatically reset between tests, we can end up with tests that do not specifically turn the flag on or off then randomly running with the flag on depending on the order in which our tests are executed. For most tests, this won’t make a difference, but for some, it will and we could get failures in our build that do not make sense because we cannot see from the single test’s code that the flag was left on by another test before it ran.
Note also the careful wording of this rule: we don’t always disable the flag at the end of the test; we set it back to what it was before the test. Being disciplined in resetting the flag is crucial to making the next tip work.
Run the whole build with the feature flag ON
Once we think we have created pre-feature and post-feature versions of all the test suites that we believe are affected by the feature flag, we need to run the whole build with the flag ON. This will flush out tests that are affected by the flag where we have not yet created a divergent suite. If we have been sufficiently comprehensive in our test modifications, nothing should fail, because all tests of paths that care about the flag should already be explicitly setting the flag in the test.
API, Integration and End to End Tests
These tests are executed against a deployed and running instance. This instance is connected to a Feature Flag server.
We will use strategies described in previous section to perform different types of testing, for example: ensure that we can deploy to production (Production state strategy) or that new implemented features do not break anything (Next release candidate strategy).
The challenge with this type of tests is when we have to implement new tests for a new feature that will be visible or not depending on the test strategy selected.
This challenge becomes more complex when a new feature changes a functionality that affects existing cases.
In both situations, we could decide disabling affected test cases and running them manually against proper strategy.
However, disabling tests means losing test coverage, increasing probability of weaker deliverables. As alternative, we propose implementing toggle logic in the test.
Implement Toggle In The Test
Tests affected by a toggle must implement two versions: one testing logic with flag OFF (current logic) and the other one with flag ON (new logic). Strategy selected defines the value (ON/OFF) of the flag and this value sets which version of the test (ON or OFF) should be executed; the other version should PASS (skipping the test).
Make a copy of every affected test
We will handle these tests in the same way than unit tests: affected tests will be cloned, new test implemented in the original file and old logic in the new file (see Unit Tests section for more details).
Testing in Production
Testing features in a pre-production environment presents a challenge: we are never able to fully reproduce the production environment that our actual users live in. We do not have the same data, nor the same usage (load) and probably architecture might be also different. Feature flags present us with a solution to this problem: we can do our testing in production!
Testing in production does not mean shipping code with no tests into production and hoping for the best. Instead, it means having the ability to have real users test real features, with real data, in a real environment.
With Testing in Production, we can measure impact or identify issues even before they affect our users (see Rollout section).
Overlapping Feature Flags
There are situations where two or more feature flags may require modifying same piece of code or a set of tests.
In these situations, team has to decide how to face them. There is no standard way to do it. However, these guidelines may help us implementing the overlapping:
- Clean before implementing: if one of the overlapping flags has been already rolled out (released in production and available for all users and all transactions), then evaluate whether we can clean it up (remove) before implementing new flag.
- Check dependencies: if one flag is required (requiredFlag) by the other (dependantFlag), then we could implement the other flag as part of the required flag.
if(requiredFlag) {
if(dependantFlag) {
requiredAndDependantFlag();
} else {
requiredFlag();
}
} else {
preRequiredFlag();
}
- Merge flag: In order to simplify the implementation, team could agree to roll out overlapping flags together, so they will be implemented under same flag.
- Decide rollout strategy: Team may decide a queue where a feature cannot be activated in production until the other overlapping flag has been rolled out and cleaned up; simplifying the complexity of implementation, testing and rolling out.
- Implement combinations: There will be situations, especially when overlapping flags are critical and we want to rollout as soon as one flag is ready, where we have no choice than implementing combinations in order to cover any rollout combination.
if(flagOne && flagTwo) {
flagOneAndFlagTwo();
} else if(flagOne) {
flagOne();
} else if(flagTwo) {
flagTwo();
} else {
originalCode();
}
These overlapping situations become much more complex as the number of overlapping flags increase.
Testing Overlapping
Testing strategy depends on the plan chosen for coding the overlapping. Test must follow same approach, i.e. clean, merge, check dependencies, implement combinations or whatever it has been decided.
We may also face the situation where overlapping only happens in tests. Then, team should also select the strategy.
Key Takeaways
- Never reuse a feature flag.
- Minimize when flag is used in the code.
- Do not test all toggle combinations.
References
- The Split Blog
- Feature Toggles (aka Feature Flags)
- A Practical Guide to Testing in DevOps, by Katrina Clokie
- Feature Flag Best Practices, by Pete Hodgson & Patricio Echagüe
- Managing Feature Flags, by Adil Aijaz and Patricio Echagüe
