
Introduction
DevOps comes from putting together development and operations teams. Traditionally these two teams have opposite objectives: development wants to deliver changes as fast as possible and operations tries to keep system stable and secure. Then we could summarize DevOps as the capacity of moving fast, keeping the system stable.
The word “DevOps” was coined in 2009 by Patrick Debois, who became one of its gurus. Patrick held the first DevOpsDays event in Ghent that lit the fuse. However, the seeds of DevOps were planted long time ago.
DevOps represents a change in IT culture, focusing on rapid IT service delivery through the adoption of agile, lean practices in the context of a system-oriented approach. DevOps emphasizes people (and culture), and seeks to improve collaboration between operations and development teams. DevOps implementations utilize technology— especially automation tools that can leverage an increasingly programmable and dynamic infrastructure from a life cycle perspective.
Gartner Glossary
There is not enough with a definition to perform DevOps, there is not a unique receipt, a list of practices nor a set of tools. DevOps is about people, culture, and mindset, is about processes and also is about tools. How each team or company puts it in practice will be very different as the environment, the culture, the project have an impact.
Objectives
The goal is to enable and sustain a fast flow from development into operations without causing chaos and disruption in the production environment. This means reducing the risk associated with deploying and releasing changes into production.
DevOps is modern application development
The objectives are to produce low risk releases, reduce lead time and obtain fast feedback; making deployment and releases into production a routine part of daily work.
The way to do this is by creating the foundations of automated deployment pipelines. Ensuring that they have automated tests that constantly validate that we are always in a deployable state; in other words this is integrating the objectives of QA and Ops into everyone’s daily work, reducing firefighting and making people more productive.
It is important to succeed to make sure that the easy path is going to be the path that is the most secure, the most reliable and the most predictable. It has to be easy and straightforward performing the defined steps, exceptions and shortcuts do not have to be worth it.
The Journey
Achieving DevOps success is not a single step, but a journey. We have to start stablishing where we are and what we want to achieve.
It is important that people understand the why and where we are going.
This post describes some basic pillars to sustain the DevOps journey.
Where We Are
Look at what you are currently doing and define it, name it. Identify those people and their roles. The flow and momentum of the organization is huge, align with what the organization does well already; or what kind of DNA the organization is if it works that way, get it use that to your advantage. Part of this is get outside of our IT shell and think not just what the end that is in mind, that you’re starting from, but what’s the ultimate value that is important to the business and work backwards from that.
In our current situation is easy to identify bottlenecks, manual steps and separated responsibilities, normally depending on different people (development, testing and operations).
What Do We Want To Achieve
The proposal to embrace DevOps is to define an initial objective: implementing continuous deployment. Processes, phases and practices required, including continuous integration and continuous delivery, will settle the foundations to perform DevOps.

By Continuous Deployment, we mean deploying into the production environment any committed change. This requires that code deployment to be automated, repeatable and predictable, a low risk process.
These are the fellow travelers that will accompany us on this journey:
- CI/CD
- The DevOps Team
- Trunk-base development
- Testing
- Deployment
- Definition Of Done
Continuous Integrations/Continuous Delivery
Continuous Integration (CI) is a software development practice where developers regularly merge their code changes into a central repository, after which automated builds and tests are run. CI entails both an automation component (building an artifact) and a cultural component (learning to integrate frequently). The key goals of continuous integration are to find and address bugs quicker, improve software quality, and reduce the time it takes to validate and release new software updates.
It follows the principle that if something takes a lot of time and energy, you should do it more often, forcing you to make it less painful. By creating rapid feedback loops and ensuring that developers work in small batches, CI enables teams to produce high quality software, to reduce the cost of ongoing software development and maintenance, and to increase the productivity.
Continuous Delivery (CD) is a software development practice where code changes are automatically prepared for a release to production. A pillar of modern application development, CD expands upon Continuous Integration by deploying all code changes to a testing environment after the build stage. When properly implemented, every change will always create a deployment-ready build artifact that has passed through a standardized test process.
Continuous delivery lets developers automate testing beyond just unit tests so they can verify application updates across multiple dimensions before deploying to customers. These tests helps validating updates and pre-emptively discover issues.

CI/CD is one of the most critical practices that enables the fast flow of work in our value stream.
Code: Trunk-based developments. Only one main branch where developers must merge their changes frequently.
Build: Our deployment pipeline must create packages from version control that could be deployed to any environment, including production.
Test: Anyone should be able to run any or all of our automated test suites, locally or on the test systems.
Deploy: Anybody should be able to deploy these packages to any environment where they have access. Executed by running scripts that are also checked in version control.
The key to success is: Automate! Automate! Automate!
Automation is the single biggest driver of high performance, increasing the overall quality and speed of code deployments. Greenfield environments have the advantage of not being bogged down by legacy processes and technical debt, but even established organizations can make incremental improvements using automation. Automate a single pain point. Start small, prove the value, and use the visibility that success brings to tackle bigger improvements.
The DevOps Team
Almost everyone agrees that culture is the most important ingredient of DevOps. Culture is present in the team. A generative culture (Types of Organizations, Westrum, 1994) is key to be success implementing DevOps. A team that shows a generative culture is performance oriented will have some of the following behaviors:
- high cooperation
- messengers trained (no blaming)
- risks are shared
- bridging encouraged (breaking down silos)
- failure leads to inquiry
- novelty implemented (experimentation)
The biggest impediment to create innovative software is how testing is implemented:

Under DevOps, is key that Testing has to be organized in a different way.
Quality is everyone’s responsibility. Improve quality, you automatically improve productivity.
W. Edwards Deming
The whole team is responsible of making pipeline pass, in other words: testing, operations and security for all.
Conway’s law explains very well what is behind the DevOps concept: development + operations:
Any organization that designs a system (defined broadly) will produce a design whose structure is a copy of the organization’s communication structure.
Melvin E. Conway
For example, in a organization with three teams (development, testing and operations), according to this law, the process required to release a change into production, will have 3 separated stages (one for each team), and these stages will be poorly coupled.
It is key applying behaviors of a performance oriented team (collaboration, shared responsibilities, …). DevOps tears down the silos that have traditionally existed between all the teams involved in software delivery (development, quality and operations).
«Pair to Program, Mob to Learn»
Trunk-Based Development
Trunk-Based Development is based on having one main branch, where developers merge small changes continuously, rather than working on long-lived feature branches.
«If you are not committing at least once per day, you are not doing continuous integration»
The long the developers are allowed to work in their branches in isolation, the more difficult it becomes to integrate and merge everyone’s changes back into trunk.
In fact, integrating those changes becomes exponentially more difficult as we increase the number of branches and the number of changes in each code branch.
Integration problems result in a significant amount of re-work to get back into a deployable state. Including conflicting changes that have to be manually merged, or merges that break out automated or manual tests, usually requiring multiple developers to successfully resolve.
And because integration has traditionally been done at the end of the project, when it takes far longer than planned, we are often forced to cut corners to meet the release date. This causes another downward spiral, when merging code is painful we tend to do it less often, making future merges even worse.
Continuous integration was designed to solve this problem, by making merging into trunk a part of everyone’s daily work. All developers commit their code at least once per day. Detecting merge problems when they are small, allows correcting them faster and avoiding the rework of merging conflicts and the delayed feedback that is received from the deployment pipeline.
Testing
In Trunk-Based developments there are no branches, just a long, unbroken straight line of development. Each commit can break the entire project.
To be effective and release good code it is critical using feedback that continuous integration gives. Feedback requires to build more effective automated testing.
Without automated testing, continuous integration is the fastest way to get a big pile of junk that never compiles or runs correctly.
The key to DevOps? Testing early in the pipeline: test early, test often and test everywhere. The later a bug is caught in the development cycle, the more expensive it is to fix:

Shift-left testing
Shift-left testing helps detecting errors early. It enables continuous testing, saves time, money and improves team collaboration.
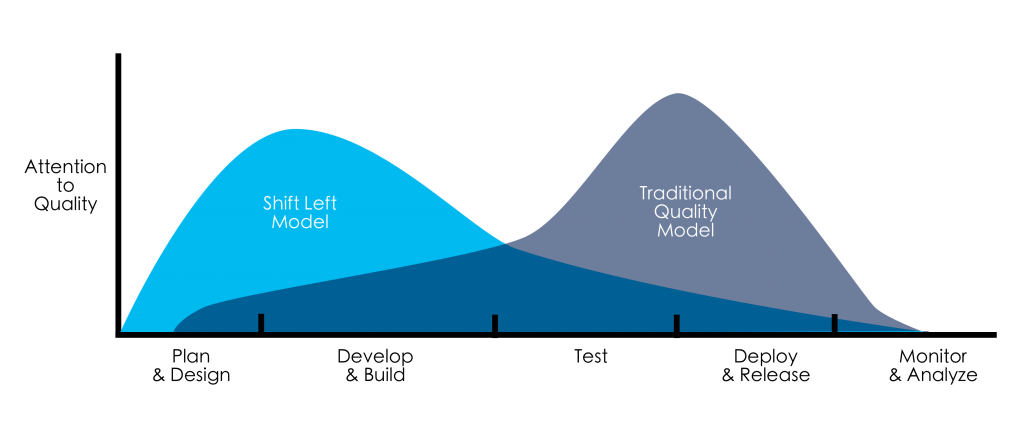
The key to achieve shift-left testing is automation. However, there is not enough with automated and reliable tests. They should provide fast feedback.
The way to perform shift-left testing is to implement different test types, with different test scopes. Different test types are expressed in the Test Pyramid:
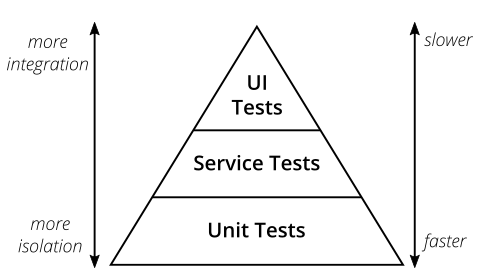
The idea is to execute pyramid levels from bottom-up, as early as possible in the pipeline, i.e. start with the fastest and most decoupled tests (unit tests) and finish with the slowest and more integrated tests (end to end or UI tests), after passing previous test levels.
This must be translated into a change in the testing methodology that normally is used in the development software, where there is a separated stage for testing and, normally, is executed by a separated team. In a DevOps team, quality is responsibility of each team member.
If you focus on quality, the speed will come.
If you focus on speed, quality gets lost.
Janet Gregory
Security
Normally, Software Development Life Cycle (SDLC) and Application Security (AppSec) are disconnected. What started as small innovation gap, 15-20 years ago, has become a chasm. This fact is one of the core roots of the disconnect:

The consequence of the disconnect is that most of the companies are releasing code at a pace at which we are not able to keep up with security scans.
Companies are attempting to secure code very late, once it is already in production, detached from SDLC. Vulnerabilities found by this analysis are passed to the development team, not connected to the SDLC, not knowing which developer introduced that vulnerability.
Vulnerabilities
Vulnerabilities are not provoked only by our developers. Developers use open source software. Open source components are not created equal: some are vulnerable from the start, while others may go bad over time.
Similar to Test, the late vulnerabilities are fixed, the most affects productivity (increasing cost):

In practice, many vulnerabilities are introduced in the development phase accidentally or due to a lack of securing code knowledge. So, practically speaking, if the team focus in the development phase, productivity can improve by 2.3 or by 15.4, compared to next phases.
DevSecOps
DevSecOps or Security As Code is about DevOps with the lens on security.
Essentially, DevSecOps is a philosophy that ensures security as code culture and integrates security into DevOps processes. Changes are tracked, identifying places where we can add security (tests and checks).
“Security as code is really about making security more transparent, to work with developers, and speak the same language. We really need to give them the tools and the security policies so they know what to do and can do it themselves.”
Francois Raynaud, founder, DevSecCon
As a result, team will deliver small and secure pieces of code in frequent releases.
Automate the security process whenever possible, building guardrails instead of gatekeepers.
As we have seen for Testing, Security is responsibility for the whole team: Make security everyone’s responsibility.
Why
Establishing security protocols as the primary ingredient of the development lifecycle allows teams to write secure code from the start. Then the team can:
- detect bugs and vulnerabilities at earlier stages and fix them at a lower cost
- confidently use open-source packages with an automated tool to track harmful components
- prioritize security for developers, increasing their security expertise at the same time
- manage risks
How to start
A first proposal could be:
- Automate static and dynamic analysis, and penetration testing to be able to reuse it across all environments.
- Create a continuous feedback loop to allow developers to fix issues and learn the best security practices while coding.
- Monitor automated security policies and ensure sensitive data is protected.
- Test on every code commit and within a staging environment.
- Automatically create logs during continuous security monitoring.
Deployment
With traditional methods of software development, deployments are often infrequent, painful, and disruptive events.
There is a high correlation between performance and deployment pain: the more painful code deployments are, the poorer IT performance, the organizational performance and culture. Furthermore, painful deployments result in higher change fail rates.
Common problems include:
- Changes that often result in failures and are difficult to diagnose and fix.
- Dev, test, and staging environments that are different from production environments, causing failures when builds are promoted across environments.
- Lots of manual work required to deploy.
- Many handoffs between teams, resulting in slow, inefficient deployments.
Because it is painful, we tend to do it less and less frequently, resulting in another self-reinforcing downward spiral
By deferring production deployments, we accumulate even larger differences between the code to be deployed and what is running in production, increasing the deployment batch size.
As deployment batch size grows, increases the risk of unexpected outcome associated with this change, as well as the difficulty fixing them.
Deployment pain is reduced when implementing Continuous Delivery practices: comprehensive test and deployment automation, the use of continuous integration including trunk-based development, and version control of everything required to reproduce production environments. A part from the Continuous Delivery practices, countermeasures that should be implemented include:
- Do smaller deployments more frequently (i.e., decrease batch sizes).
- Automate more of the deployment steps.
- Treat your infrastructure as code, using a standard configuration management tool.
- Implement version control for all production artifacts.
- Implement automated testing for code and environments.
- Create common build mechanisms to build dev, test and production environments.
Deployment Goals
Our deployments should pursue following goals:
- Avoid Downtime (planned or unplanned)
- Get Early Feedback and Limit Impact
- Learn In The Process
Blue/Green deployment, Canary deployment and Feature Flags are techniques that can help achieving the deployment goals.
Continuous Deployment
We will enable the promotion into production of any build that passes our automated tests and validation process either on demand (by pushing a button) or automatically (any build that passes all validations is automatically deployed into production).
Deployment process must be automated and it must be executed for all the environment: deploying the same way to every environment.
Smoke testing the deployment: during the deployment, we should test that we can connect to any supporting system (like db, message buses, …) and run a single test transaction through the system to ensure that our system is performing as desired.
Feature Flags
Decoupling deploy (moving bits around your infrastructure) from release (exposing those bits to users). It is an essential foundation to practice in modern software delivery. In the near future, every deployment will happen behind a feature flag.
deployment != release
With Feature Flags, changes are deployed into production, but new features are hidden behind a feature flag. This logic is added to the application code and is controlled by an if/else statement (for each change added under the new feature).
Rolling back a feature release does not require additional deployments, just disabling the flag, feature is hidden.
Enabling or disabling feature flags is detached from the deployment of changes. You chose exposing new features to different groups of users/endpoints for different purposes (final smoke test, check that delivered feature is what is expected, AB testing…).
Feature flags provide:
Deployment Safety
- The kill switch (reactive): turn off «bad» code
- Gradual Rollouts (proactive): gradually expose features (internal, beta users…)
Deployment Speed
- Better CI process: trunk-based development, merge incomplete code into main branch (avoiding long lived feature branches)
- Release predictability: testing in production
Experimentation and Customization
- Experimentation: Fast feedback loop
- Segment features based on licensing, geolocation, …
Definition Of Done
New definition of done could be: Keep code in a deployable state. Expanded: keep code integrated, tested, working and potentially shippable, demonstrated in a production like environment, created from trunk, using a one-click process and validated with automated tests.
Keeping the code in a deployable state, we are able to eliminate the common practices of separate test and stabilization phase at the end of the project.
Continuous Improvement
Start with foundations, and then adopt a continuous improvement mindset by identifying your unique constraint (or set of constraints). Once those constraints no longer hold you back, repeat the process.
You cannot improve what you cannot measure. Without measure, you cannot demonstrate improvement. You can only measure what is Done.
Metrics
The reason to adopt DevOps is that we are looking to improve our current situation. The only way to validate this improvement is to measure it.
The DevOps Research and Assessments (DORA) team is the author of the State of DevOps report. This report is published every year and analyzes evolution of DevOps adoption and the impact on the performance.

Software delivery performance is obtained using four metrics: the DORA metrics.
DORA metrics
The first four metrics that capture the effectiveness of the development and delivery process can be summarized in terms of throughput and stability. We measure the throughput of the software delivery process using lead time of code changes from check-in to release along with deployment frequency. Stability is measured using time to restore —the time it takes from detecting a user impacting incident to having it remediated— and change fail rate, a measure of the quality of the release process.
Measuring performance of a team is not an easy task. It depends on the project, if there are other teams working on the same project. Therefore, it is challenging to tell who is doing what and when, where the blockers are, and the waste that causes delays to the process. Essentially, it is nearly impossible to see how each piece of the application development process puzzle fits together.
DORA metrics can help shed light on how your teams are performing in DevOps.
These metrics are a result of several years worth of surveys conducted by the DORA team, that, among other data points, specifically measure Deployment Frequency, Lead Time, Mean Time To Recover and Change Failure Rate. These metrics guide determine how successful a company is at DevOps – ranging from elite performers to low performers:

Deployment Frequency: how often the team deploys code to production.
Lead Time for changes: It is the time in between a commit has been made, and this code gets into production.
Mean Time To Restore (or MTTR): Is the mean time that is needed to go back to service when there has been a failure in production. For example, the time that we need to recover from a broken database or from a commit that breaks a feature.
Change Failure Rate: percentage of changes that go to production and require fixes.
Other metrics
Cycle Time: It is the elapsed time since a change has been committed and pipeline has finished.
Flow Efficiency: relation between working time and lead time (or relation between periods where we add value and total time required to finish a feature).
Blocked Time: period where a feature has been blocked by external dependencies.
Change Rate: similar to Change Failure Rate, this metric a part from the fixes includes improvements or change requests.
WIP Age: average lifetime of the ongoing work in progress features.
Conclusions
Any change committed to the main branch will trigger a pipeline that will validate it. Passing this validation will allow keeping trunk in a working releasable state.
Validation of the committed change includes creating the artifact (build) and passing all the tests and security checks.
Pipeline provides fast feedback created by the automated testing.
Stablish a culture that halts all work any time a developer breaks the deployment pipeline, ensuring that rest of the team brings the system back into a green state.
Final step is to add automatic deployment into production environment in case committed change is validated (passes CI/CD pipeline).
There is not a unique receipt or a defined list of actions to be performed to adopt DevOps. Options depends on the platform, the tools, the knowledge and sometimes opportunity windows that open.
This proposal emerges from the point of view of the Development process (the Dev part). The idea is to start walking through the DevOps loop, and by getting deeper into it, the Ops part will arise, opening other paths: environments, going to cloud, automation, observability, analysis of performance, …

References
- The DevOps Handbook – How to Create World-Class Agility, Reliability, and Security in Technology Organizations, Gene Kim, Patrick Debois, John Willis, Jez Humble
- Conway’s Law, 1967
- Quality Processes in an Agile Environment, by Janet Gregory and Lisa Crispin
- VSM DevCon 2020
- State of DevOps 2019
- Progressive Delivery
